Keyword retrieval exploits frequencies and
positions of search keywords in target documents. As for retrieval by two
or more keywords, semantic relation between keywords is important to improve accuracy.
For
retrieving information about a person, it is common to search by a pair
of keywords consisting of person's name and his/her attribute of the
interest.
By using dependency analysis and coreference analysis, correct
occurrences of pairs of person and his/her attributes can be retrieved.
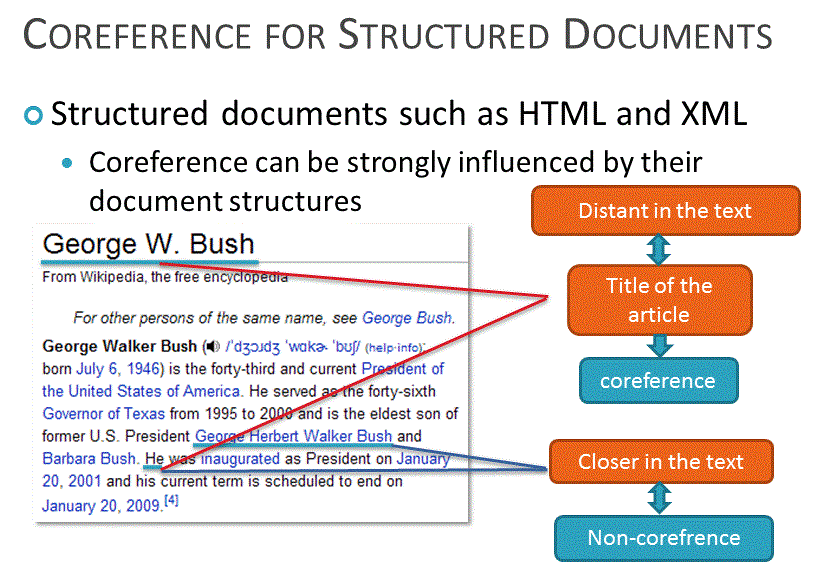
However, existing natural language analysis does not consider the factor
that logical structures of the documents strongly influence probabilistic
patterns of coreference. We propose a new way of person retrieval
by computing a maximum entropy model from linguistic features
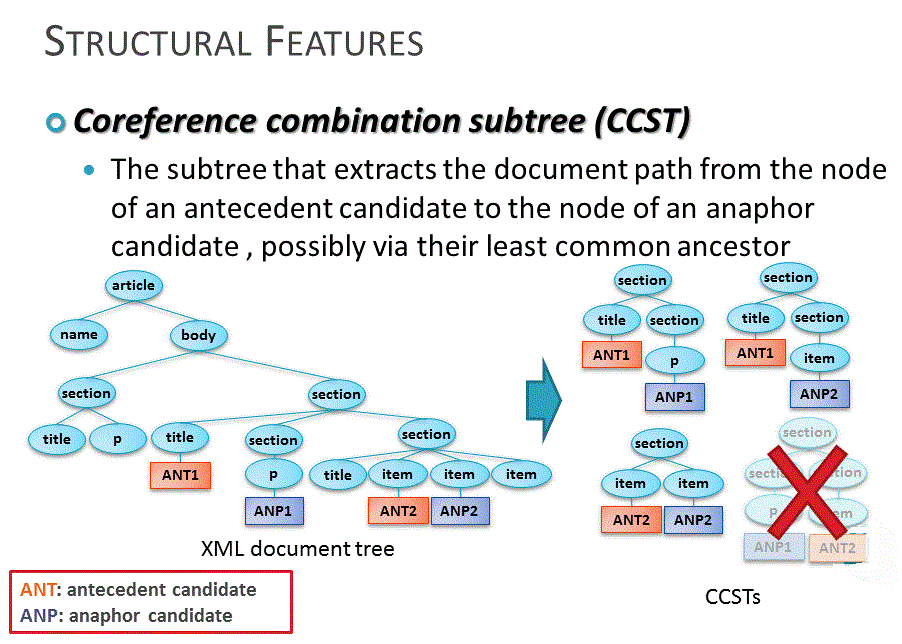
and structural features, where structural features are learned from
probabilistic
distribution of coreference over XML document structures. Our
method can utilize strong correlation between XML document structures
and coreference, thus having superior accuracy than existing methods.
文書検索では検索キーワードの出現頻度や出現位置を利用するが,2つ以上のキーワードによる検索では,キーワードの間の意味的関係が重要になる.例えば人物検索では,人物の名前とその人物の属性で検索が行われることが多い.自然言語処理の依存解析と照応解析により,正しい人物とその属性の対応を求めることが考えられるが,従来の方法では照応の確率的傾向が文書の構造に強く影響を受けていることを利用していたなかった.本研究では,人物検索への応用を目的として,XML文書の構造における照応の確率的傾向を学習し,この文書構造による素性と言語学的な素性を組み合わせた最大エントロピーモデルを求めることにより,照応分析の精度を向上している.
文書検索では検索キーワードの出現頻度や出現位置を利用するが,2つ以上のキーワードによる検索では,キーワードの間の意味的関係が重要になる.例えば人物検索では,人物の名前とその人物の属性で検索が行われることが多い.自然言語処理の依存解析と照応解析により,正しい人物とその属性の対応を求めることが考えられるが,従来の方法では照応の確率的傾向が文書の構造に強く影響を受けていることを利用していたなかった.本研究では,人物検索への応用を目的として,XML文書の構造における照応の確率的傾向を学習し,この文書構造による素性と言語学的な素性を組み合わせた最大エントロピーモデルを求めることにより,照応分析の精度を向上している.